📣 Let’s understand GPT various layers and what each layer does.
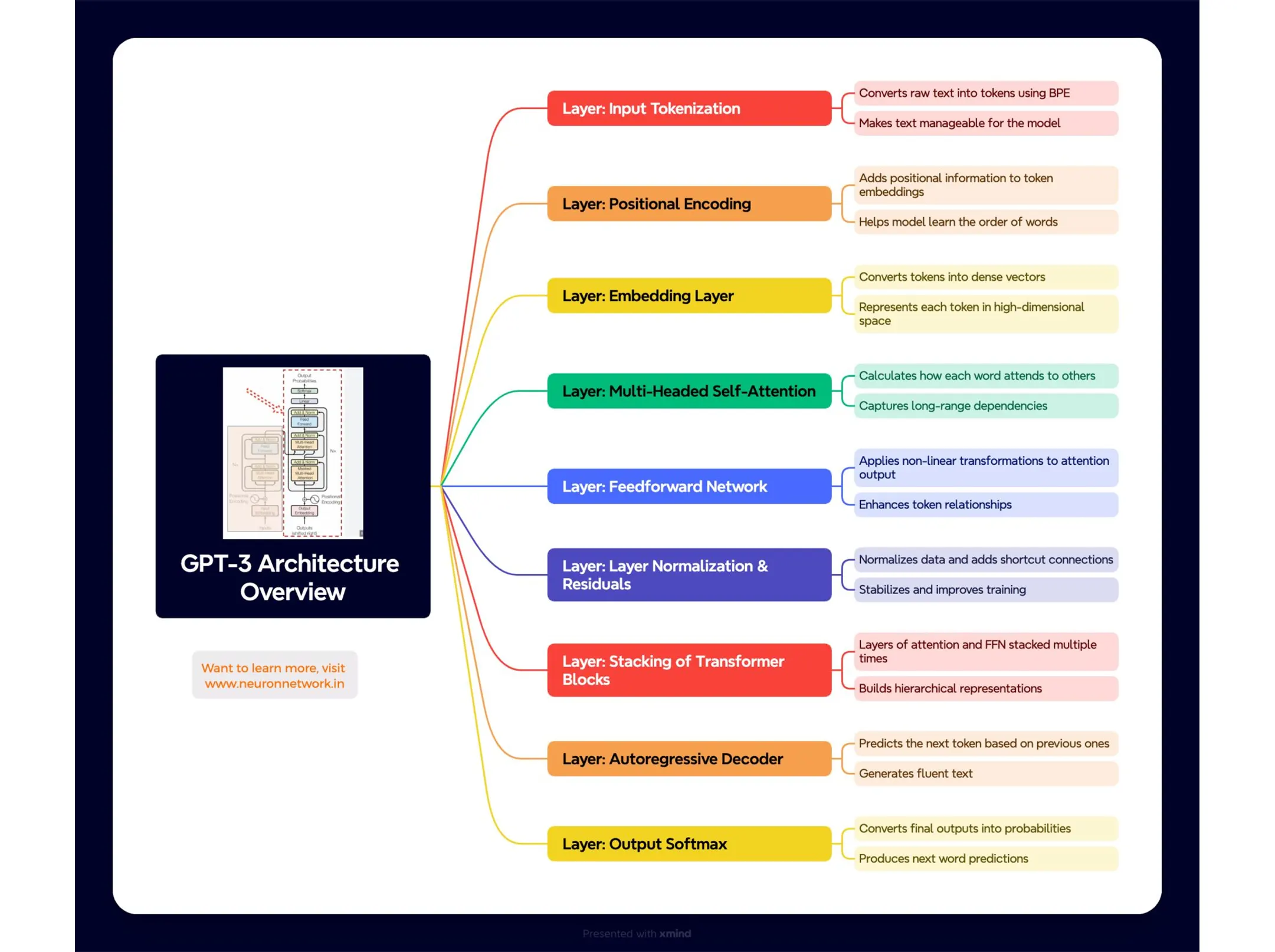
Remember, GPT is decoder only architecture, so only the right side of the original transformer picture would be accommodated.
𝗜𝗻𝗽𝘂𝘁 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Converts raw text into tokens using Byte Pair Encoding (BPE). This step breaks the input text into smaller subword units that can be processed by the model.
𝗣𝗼𝘀𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗘𝗻𝗰𝗼𝗱𝗶𝗻𝗴: Adds position information to each token embedding. Since transformers lack sequence awareness, this helps the model understand the order of words.
𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗟𝗮𝘆𝗲𝗿: Converts tokens into dense vectors in a high-dimensional space. These vectors capture semantic meaning and are used as inputs to the attention layers.
𝗠𝘂𝗹𝘁𝗶-𝗛𝗲𝗮𝗱𝗲𝗱 𝗦𝗲𝗹𝗳-𝗔𝘁𝘁𝗲𝗻𝘁𝗶𝗼𝗻: Applies multiple attention heads to capture different relationships between words. Each head independently learns different aspects of word interactions, such as grammar or context.
𝗙𝗲𝗲𝗱𝗳𝗼𝗿𝘄𝗮𝗿𝗱 𝗡𝗲𝘁𝘄𝗼𝗿𝗸 (𝗙𝗙𝗡): A two-layer fully connected neural network applied to the output of the attention mechanism. It introduces non-linearity and further refines token representations.
𝗟𝗮𝘆𝗲𝗿 𝗡𝗼𝗿𝗺𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 & 𝗥𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻𝘀: Normalizes the data and adds shortcut connections around each attention and feedforward layer. This stabilizes training and helps prevent vanishing gradients.
𝗦𝘁𝗮𝗰𝗸𝗶𝗻𝗴 𝗼𝗳 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿 𝗕𝗹𝗼𝗰𝗸𝘀: Multiple layers of attention and feedforward networks are stacked. Each layer builds on the previous one to capture hierarchical and complex relationships in the data.
𝗔𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗗𝗲𝗰𝗼𝗱𝗲𝗿: Predicts the next token in the sequence by using previous tokens. GPT-3 generates text in a left-to-right manner, making it suitable for language generation tasks.
𝗢𝘂𝘁𝗽𝘂𝘁 𝗦𝗼𝗳𝘁𝗺𝗮𝘅: Converts the final logits (model outputs) into probabilities. The token with the highest probability is selected as the next word in the sequence.