Draft
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry’s standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into […]
𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 in 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Intuition behind.

💡𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 in 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Intuition behind. Regularization 101 definition : Model does well on training data and not so well on unseen data. Overfitting 🙂 But is there more to that, Let’s figure out. Remember that one guy in school who memorized everything what is mentioned in books or uttered from teacher’s mouth. But didn’t perform well […]
𝗪𝗲𝗶𝗴𝗵𝘁 𝗜𝗻𝗶𝘁𝗶𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 in Deep Learning:
💡 𝗪𝗲𝗶𝗴𝗵𝘁 𝗜𝗻𝗶𝘁𝗶𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 in Deep Learning: What is it and why you should care about it ? Let’s start with 𝘄𝗲𝗶𝗴𝗵𝘁𝘀. Those 𝗳𝗹𝗼𝗮𝘁𝗶𝗻𝗴 𝗽𝗼𝗶𝗻𝘁 numbers which model learn during training and somehow encapsulates the magic of deep learning. But, what’s the value of those floats when we start the training? Should it be randomly set? […]
𝗗𝗶𝘀𝗰𝗿𝗶𝗺𝗶𝗻𝗮𝘁𝗶𝘃𝗲 vs. 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 Models – A simple and intuitive explanation!!!

𝗗𝗶𝘀𝗰𝗿𝗶𝗺𝗶𝗻𝗮𝘁𝗶𝘃𝗲 vs. 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 Models – A simple and intuitive explanation!!! Imagine you and your friend work at a bank. Your job is to detect fraudulent Transactions. You are expert in identifying whether a specific transaction is fraudulent or not based on patterns in past transactions. Your friend’s job is to observe customer spend. He is […]
Are you a 𝗕𝗮𝘆𝗲𝘀𝗶𝗮𝗻 or 𝗙𝗿𝗲𝗾𝘂𝗲𝗻𝘁𝗶𝘀𝘁? Time to find out.
Are you a 𝗕𝗮𝘆𝗲𝘀𝗶𝗮𝗻 or 𝗙𝗿𝗲𝗾𝘂𝗲𝗻𝘁𝗶𝘀𝘁? Time to find out. Imagine you’re playing a game of darts at a carnival with your friends. The goal? Hit the bullseye. Now, imagine two of your friends came along with you —Kramer, the Bayesian, and George, the Frequentist. Kramer, relies on past experience. He says, “I’ve played this […]
𝗟𝗟𝗠𝗢𝗽𝘀: A Friendly Introduction

🚀 𝗟𝗟𝗠𝗢𝗽𝘀: A Friendly Introduction So, you heard the buzz around LLMOps from your friends or colleagues and wondering what the fuss is all about. Let’s dig in. 𝗙𝗶𝗿𝘀𝘁, 𝗪𝗵𝗮𝘁 𝗶𝘀 𝗶𝘁? Think of it as the next evolution of MLOps which in itself was an evolution of DevOps tailored for ML. MLOps is further tailored specifically […]
Loss Function in Machine Learning
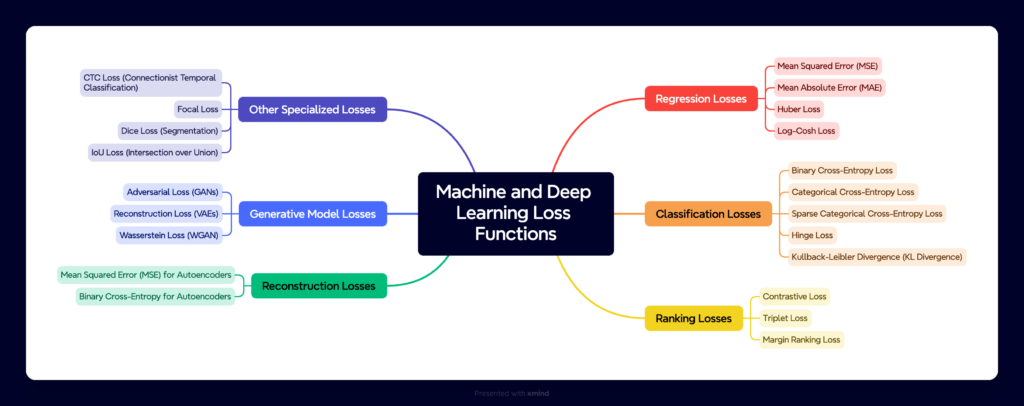
🔍 What are 𝗟𝗼𝘀𝘀 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻𝘀 and Why Do They Matter in Machine Learning? In machine learning and deep learning, a loss function is the “compass” that guides the learning process. It tells our model how far off it is from the “right” answer, adjusting weights to improve predictions with every step. Models aim to predict […]
GPT: A Layer-by-Layer Breakdown
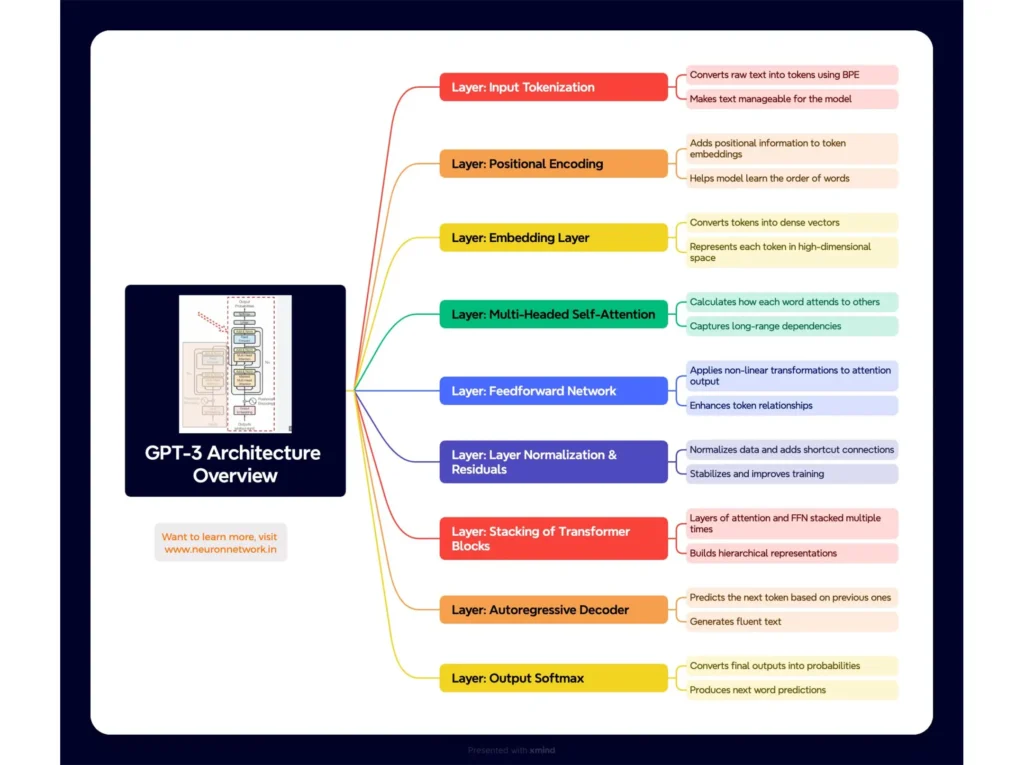
📣 Let’s understand GPT various layers and what each layer does. Remember, GPT is decoder only architecture, so only the right side of the original transformer picture would be accommodated. 𝗜𝗻𝗽𝘂𝘁 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Converts raw text into tokens using Byte Pair Encoding (BPE). This step breaks the input text into smaller subword units that can be […]
The Magic of Kernel Trick in SVM
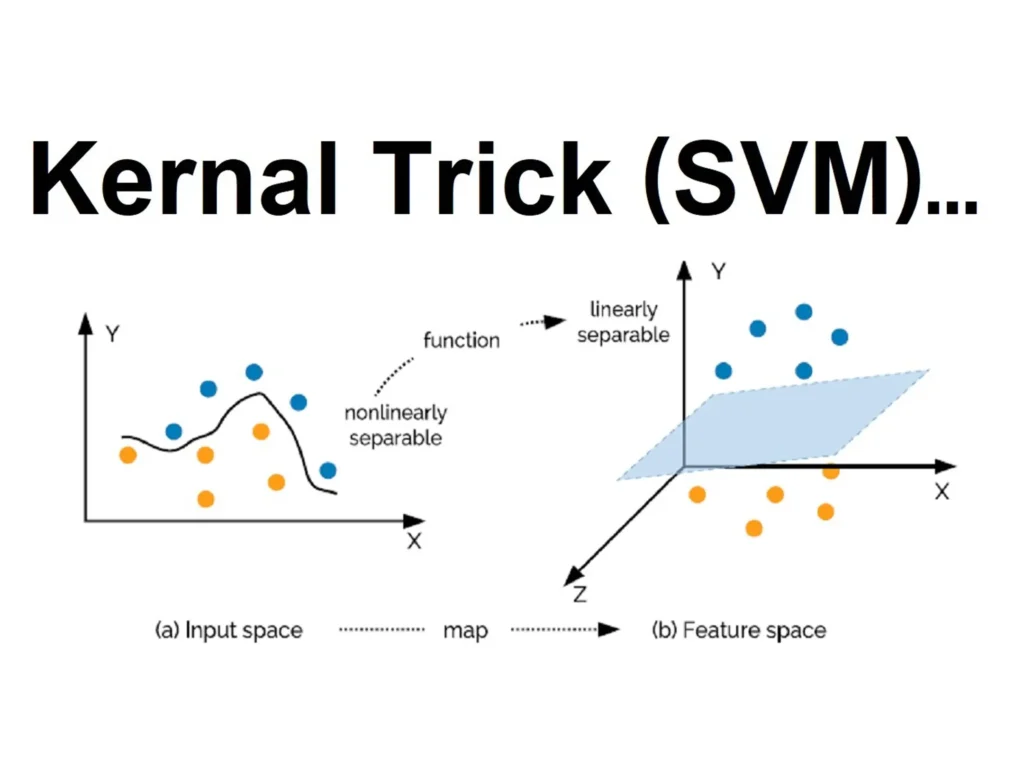
📚📚 Do you know why it is called Kernel “Trick” in SVM. You must be knowing that the “kernel” or “Kernel function” or “Kernel trick” is a method that allows Support Vector Machines (SVMs) to efficiently operate in high-dimensional feature spaces without explicitly computing the coordinates of data in that space. The kernel trick works […]
Understanding Distance Metrics: A Data Scientist’s Toolkit
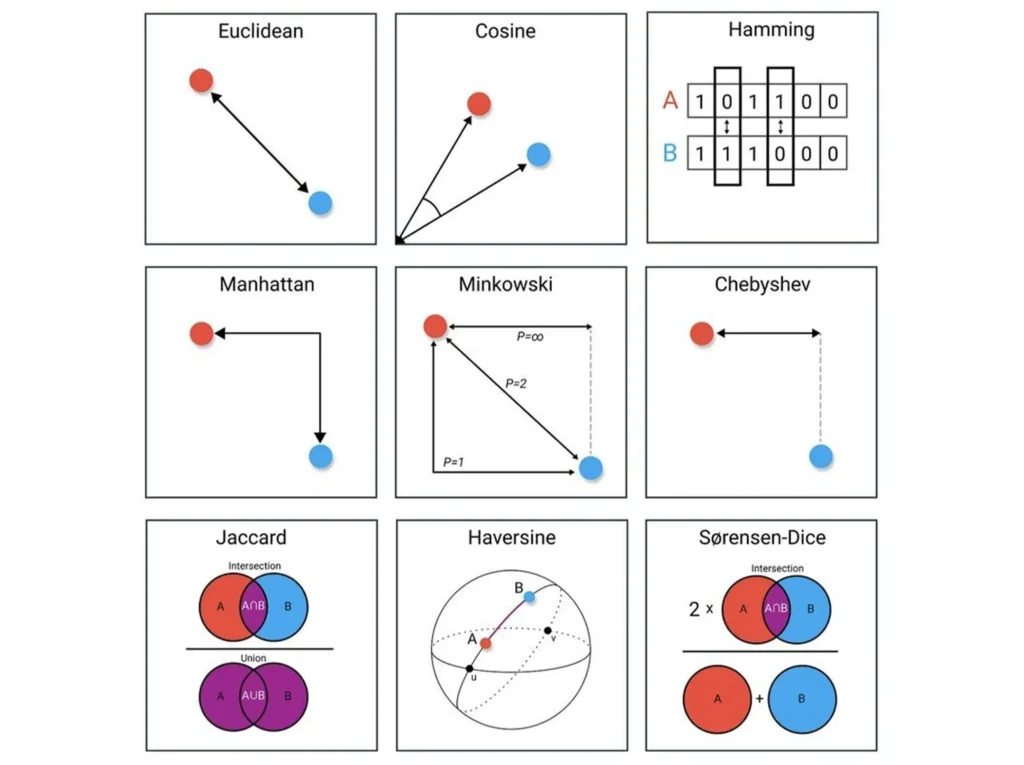
📚📚 We all know that machine learning algorithms use various distance measures to make sense of data relationships. 🧭 Let’s take a look at few popular distance measure and when these are used : Euclidean Distance: It’s like measuring the “as-the-crow-flies” distance between data points, crucial for clustering and understanding spatial relationships. 🗺️ Cosine Similarity: […]