🔍 What are 𝗟𝗼𝘀𝘀 𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻𝘀 and Why Do They Matter in Machine Learning?
In machine learning and deep learning, a loss function is the “compass” that guides the learning process. It tells our model how far off it is from the “right” answer, adjusting weights to improve predictions with every step.
Models aim to predict the correct output as closely as possible. The loss function tells the model “how much it missed,” guiding it to improve by minimizing this error through training. Without loss functions, a model would have no way to measure its performance!
🤔 But, why So Many Different Loss Functions?
Different tasks, different loss functions.
1️⃣ Regression Tasks – predicting continuous values, like temperature or stock prices
2️⃣ Classification Tasks – classifying data into categories, like identifying cats vs. dogs
3️⃣ Specialized Tasks – capturing complex goals, such as reconstructing an image, finding anomalies, or handling imbalanced datasets
Different tasks have unique needs, so loss functions are adapted to suit the specific characteristics of each problem.
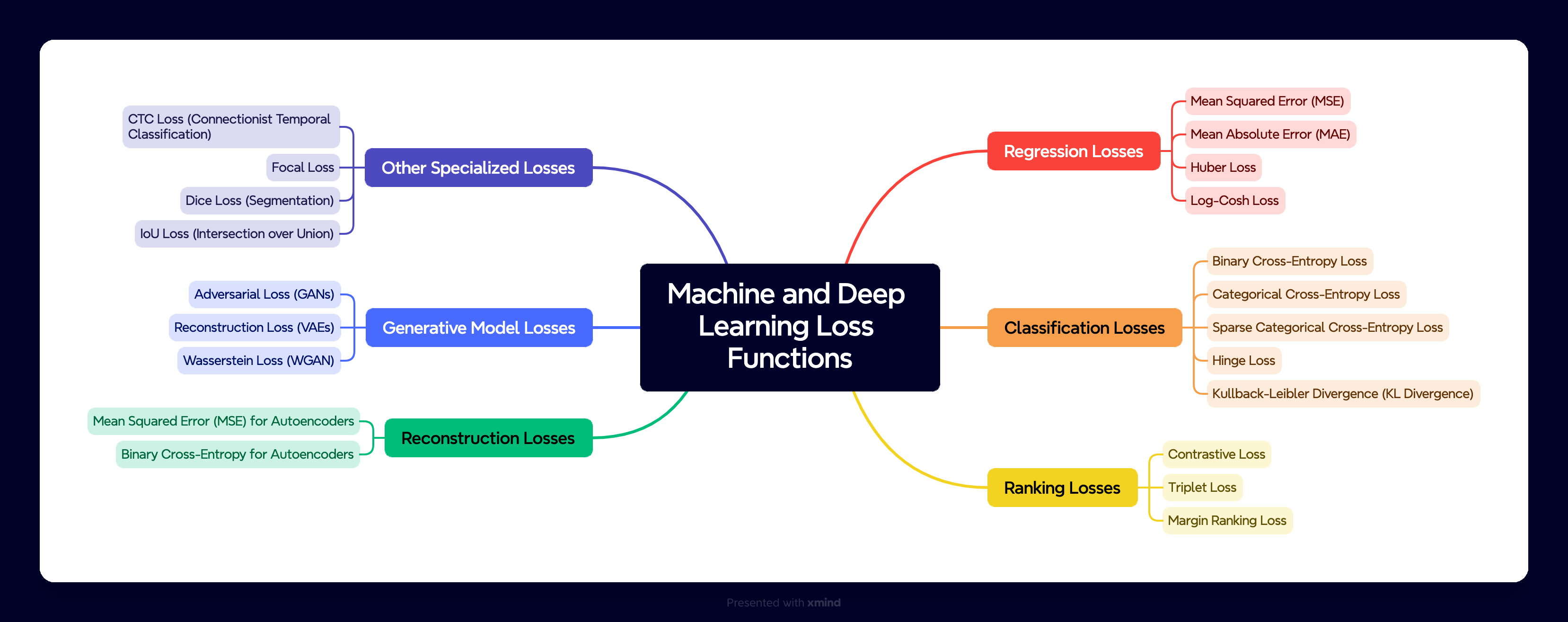
💡 Common Loss Functions in Machine and Deep Learning
1. Mean Squared Error (MSE) Loss – For Regression Tasks
MSE calculates the average squared difference between predicted and actual values. It’s like saying, “On average, how far off are my predictions?”
2. Mean Absolute Error (MAE) Loss
Unlike MSE, MAE takes the average of absolute differences. This means it doesn’t emphasize outliers as heavily as MSE does.
3. Cross-Entropy Loss – For Classification Tasks
Cross-entropy loss compares the predicted probability distribution to the actual distribution, penalizing predictions that diverge from the true answer. The higher the difference, the greater the penalty.
4. Binary Cross-Entropy Loss – For Binary Classification
This is a specialized form of cross-entropy used when there are only two possible outcomes
5. Hinge Loss – For Support Vector Machines and Binary Classification
Hinge loss penalizes predictions that are not confidently on the correct side of a decision boundary, encouraging the model to maximize the margin between classes.
6. Huber Loss – Balancing MSE and MAE for Robust Regression
Huber loss combines MSE and MAE, offering a loss function that’s less sensitive to outliers but still gives a smooth gradient
🧩 Specialized Loss Functions for DL
1. Kullback-Leibler (KL) Divergence Loss – For Variational Models and Probability Distributions
KL Divergence measures how one probability distribution diverges from another, helping models align their learned distributions with the true data distribution.
2. Cosine Similarity Loss – For Similarity-Based tasks requiring high similarity, like sentence embeddings.
3. Triplet Loss – For Face Recognition and Similarity Learning
4. Dice Loss and IoU Loss – For Image Segmentation