💡 After working for almost an year on 𝗥𝗔𝗚 (𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻), here are my thoughts:
1️⃣ Like any ML problem, you will never get good results the first time you try. It’s an iterative process.
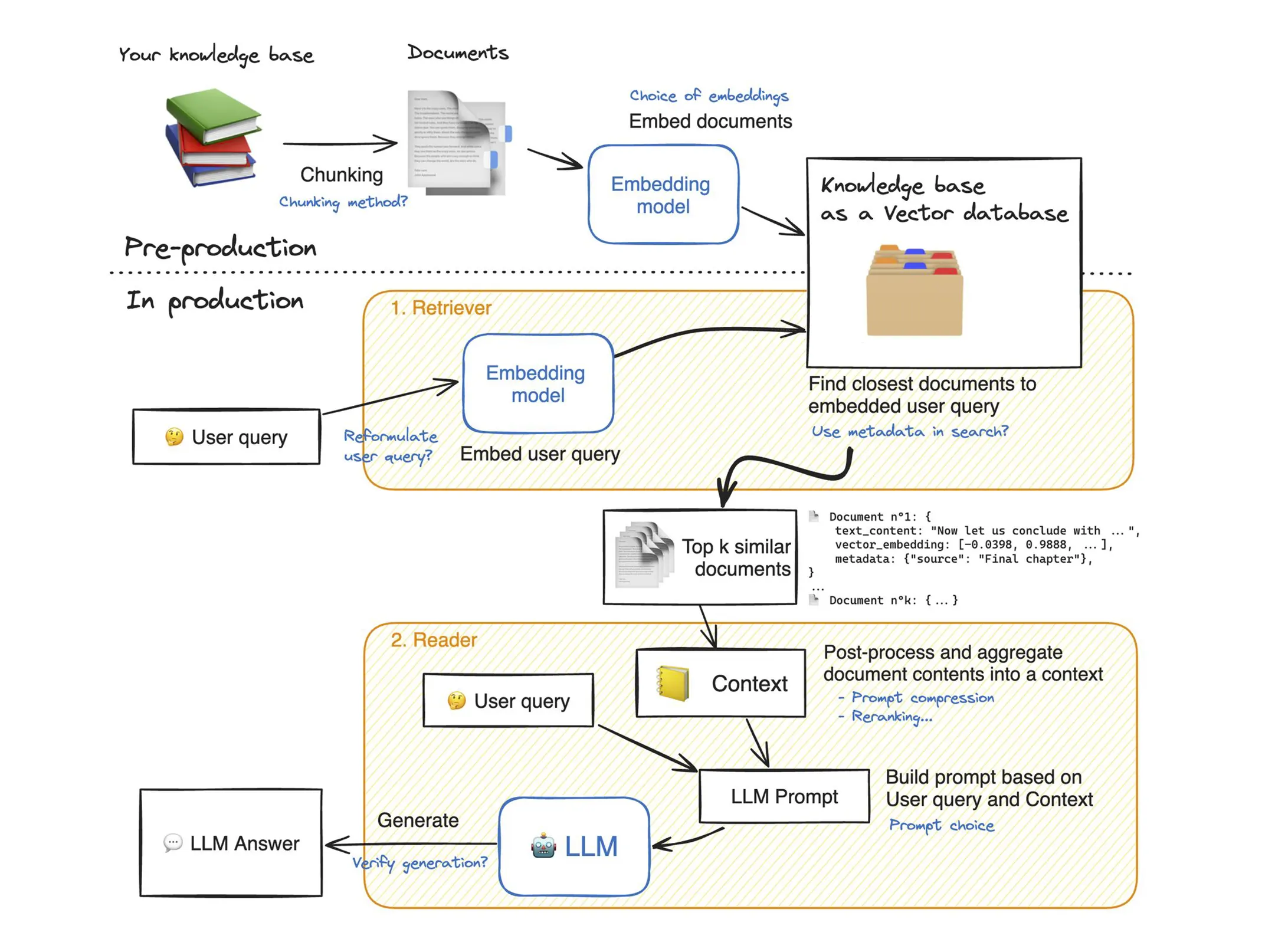
2️⃣ A whole lot depends on your chunking strategies. This determines whether your ‘chunk’ has piece of information you need to answer the question appropriately.
3️⃣ There is a trade-off between max tokens which your embedding models can take, risk of loosing context, top k documents which you want to retrieve and pass on to LLM and the context length of your LLM. These are sort of hyper-parameters which you need to tune.
4️⃣ Most of the frameworks for evaluation fall short of expectations. Keep an eye on what’s important to you as a metric. It may be well worth to do a A/B testing with beta users.
5️⃣ Try different distance measures : Cosine, Euclidean, Dot and see what works best for your case.
6️⃣ If output of RAG is fed synchronously to a system – Keep an eye on latency. LLM inference, and Vector search should be within your SLA.
7️⃣ Choose an appropriate refresh strategy for Vector DB if your Knowledge base is continuously growing.
8️⃣ Keep an eye on the cost. If your problem can be solved by simpler approaches, adopt those. Analogy which comes to mind “Do not bring gun to a knife fight” 😁
What are your thoughts? What challenges you have faced in RAG projects?